This guide is to help admins & end users make libraries unique through Flow. There are a few ways to do this however, some rely on Azure to complete, the route I’ll show only requires Owner permissions to the SharePoint site.
First we’ll need to make the library unique by breaking inheritance, then we can assign the permissions using the REST API
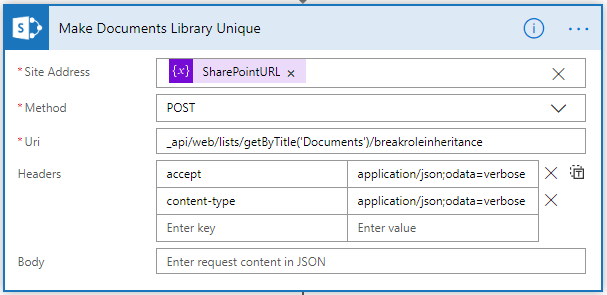
Within Microsoft Flow, add an action called ‘Send an HTTP request to SharePoint’
Enter the Site Address (https://domain.sharepoint.com/sites/IT/
Set the Method as POST
URI = _api/web/lists/getByTitle(‘Documents’)/breakroleinheritance
Ensure to change the library in brackets to your own library, the ‘Documents’ library is the out of the box library provided when a site is created
To assign permissions to the library through Flow, this can be achieved by adding another HTTP request.
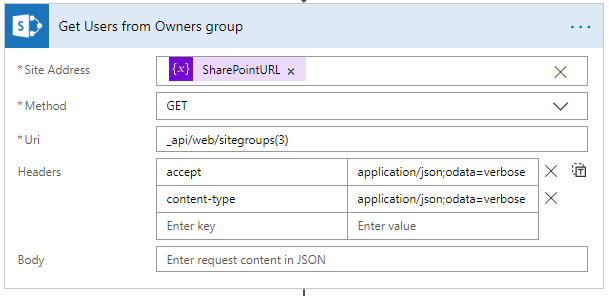
Add another HTTP request and copy the below. This will get the membership of the Owners group in SharePoint. When a site is created, by default the owners group will always have an ID of 3, the members group has an ID of 5.
Set the Method as “GET’ & the URI as ‘_api/web/sitegroups(3)”
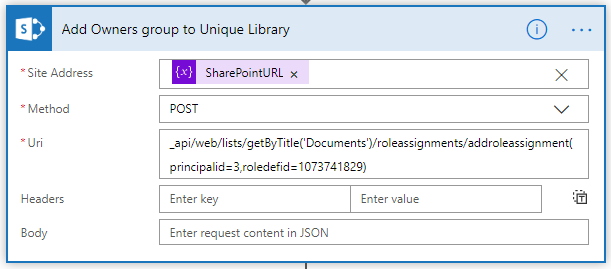
Add a third and final HTTP request to add the Owners group to the library. Set the Method as ‘POST’ & the URI as “_api/web/lists/getByTitle(‘Documents’)/roleassignments/addroleassignment(principalid=3,roledefid=1073741829)”
Note the following: The principalid is the ID of the group The roledefid for Owner permissions is 1073741829 The roledefid for Contribute permissions is 1073741827 The roledefid for Read permissions is 1073741826 The roledefid for Design permissions is 1073741828 The roledefid for Edit permissions is 1073741830 The roledefid for View Only permissions is 1073741924
Nearly every client I’ve come across has Search configured, although not every client has it running efficiently, many have errors or issues that aren’t always resolvable and result in rebuilding the Search service.
The information below will show how to recreate the Search service with minimal downtime.
This post can be used for bigger farms or even smaller farms however, adjust the PowerShell code to include the additional servers to balance the Search components. Microsoft provide a great TechNet article specifically for planning an enterprise Search service which can be found here: https://technet.microsoft.com/en-gb/library/dn342836.aspx
In this scenario we have a Search service application which does not do full crawls and just hangs unless the services on the server are restarted to which it works correctly, doing this daily is not efficient, neither should the Search Service work in this manner.
To begin with, if you have an existing Search service application, remove all the crawl schedules for all content sources.
Download the following PowerShell scripts:
export-import-mp.ps1
https://gallery.technet.microsoft.com/office/Powershell-script-to-09ffa974
export-import-cp.ps1
https://blog.lekman.com/2015/08/script-to-import-export-compare-and.html
The original script was created by Riccardo Celesti which exports/imports Search managed properties, the second script was modified by Tobias Lekman to export/import Search crawled properties. If you do not need the managed or crawled properties copied across, this stage can be skipped
Once you’ve downloaded both scripts, place them on the server in a scripts folder. While on the server, open Windows PowerShell ISE in administrator mode. You’ll need to change the directory to your scripts folder, this can be done by running “cd c:\<SharePointScriptsFolderLocation>.
Once your directory is looking at the scripts folder, type the following to export:
#Make sure the service app name is the old search service name as shown in SharePoint service applications section.
.\export-import.cp.ps1 -serviceapp “Old Search Service” -export
Once completed run the other PowerShell script to export the Managed Properties:
#Make sure the service app name is the old search service name as shown in SharePoint service applications section.
.\export-import-mp.ps1 -serviceapp “Old Search Service” -export
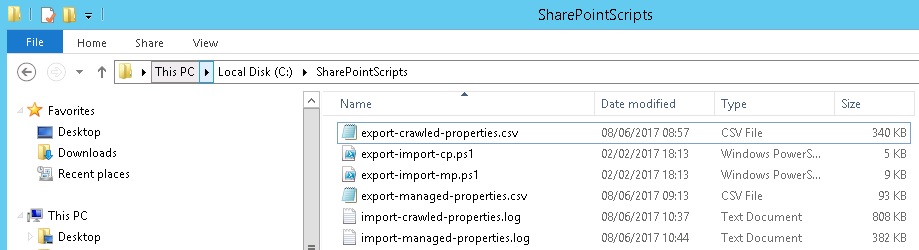
When both have been exported, check the scripts folder, you’ll notice two CSV files which are export-crawled-properties.csv and export-managed-properties.csv. If however you do not see these but the script ran successfully, it could potentially be because you never changed the directory and therefore, you’ll need to check the system32 folder for the CSV files. Within the SharePointScripts folder, you’ll also have a log file of what happened.
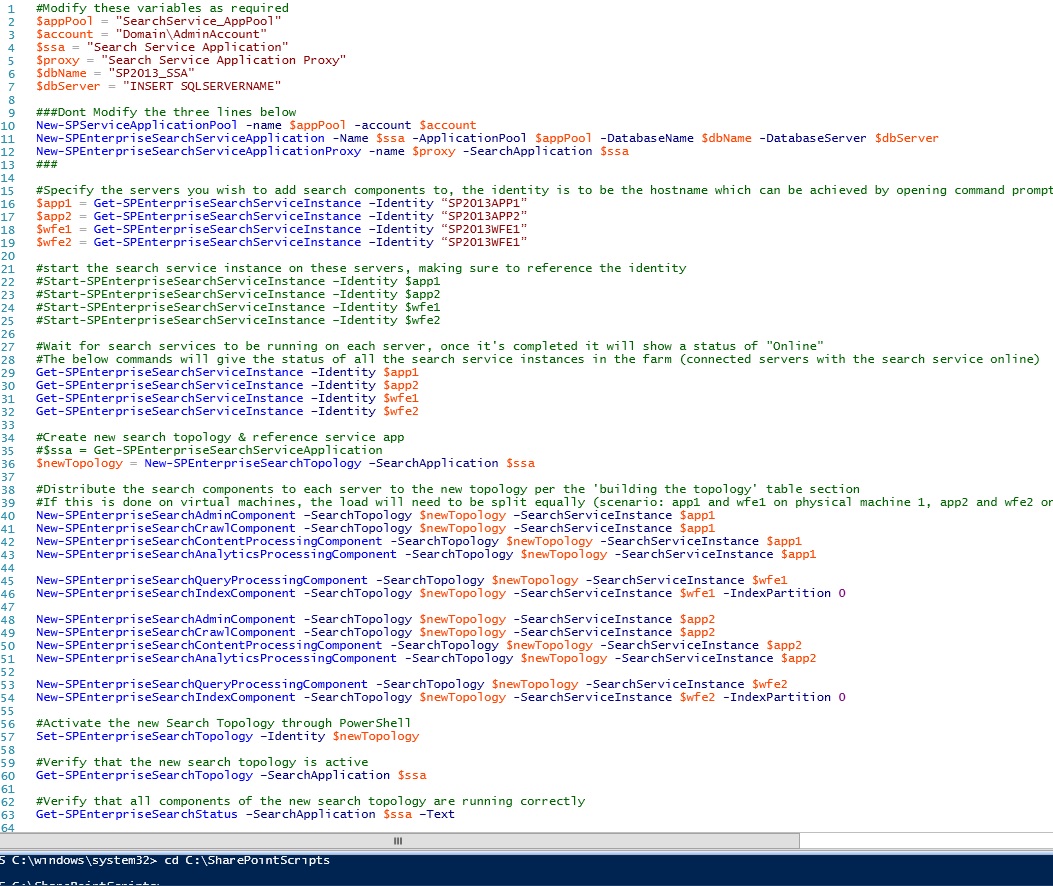
Now the managed and crawled properties have been exported, copy the PowerShell script below and paste this into PowerShell ISE (admin mode), this code will create a new Application Pool, a new Search service application, a new Search service application proxy and will also distribute the components equally to the required servers in the farm. To confirm which component you want on each virtual machine, you can check Microsoft documentation for best practices. It is worth checking the variables so they aren’t currently being used. Ensure you change the identity to the name of your servers.
The commented out sections define exactly what is happening as you run the script. You can run all the script together or in stages.
#Modify these variables as required
$appPool = “SearchService_AppPool”
$account = “domain\AdminAccount”
$ssa = “Search Service Application”
$proxy = “Search Service Application Proxy”
$dbName = “SP2013_SSA”
$dbServer = “SQLSERVERNAME”#Don’t Modify the three lines below
New-SPServiceApplicationPool -name $appPool -account $account
New-SPEnterpriseSearchServiceApplication -Name $ssa -ApplicationPool $appPool -DatabaseName $dbName -DatabaseServer $dbServer
New-SPEnterpriseSearchServiceApplicationProxy -name $proxy -SearchApplication $ssa#Specify the servers you wish to add search components to, the identity is to be the hostname which can be achieved by opening command prompt as administrator and typing ‘hostname’
#start the search service instance on these servers, making sure to reference the identity, if they’re already on, you won’t need to run the 4 lines below, these are commented out to begin with, remove the ‘#’ for the script to run this
#Wait for search services to be running on each server, once it’s completed it will show a status of “Online”
#The below commands will give the status of all the search service instances in the farm (connected servers with the search service online)
#Distribute the search components to each server in the topology.
#If this is done on virtual machines, the load will need to be split equally (scenario: app1 and wfe1 on physical server 1, app2 and wfe2 on physical server 2). Using the following scenario, each server needs a vm with AdminComponent, CrawlComponent, ContentProcessingComponent, AnalyticsProcessingComponent, QueryProcessingComponent & IndexComponent. This means the load each server deals with is completely equal to achieve high fault tolerance.
#Activate the new Search Topology through PowerShell
Set-SPEnterpriseSearchTopology –Identity $newTopology
#Verify that the new search topology is active
Get-SPEnterpriseSearchTopology –SearchApplication $ssa
#Verify that all components of the new search topology are running correctly
Get-SPEnterpriseSearchStatus –SearchApplication $ssa –Text
Once the script has completed, you’ll then need to import the crawled properties and managed properties. Run the crawled properties first, to do this, open a new window in PowerShell ISE (admin) and type:
.\export-import-cp -serviceapp “Search Service Application” -import
#Making sure that serviceapp is the name of your new search service.
Once completed, run the managed properties script as per below:
.\export-import-mp -serviceapp “Search Service Application” -import
#Making sure that serviceapp is the name of your new search service.
We run the crawled properties first as the managed properties are mapped to crawled properties, so if you attempted to run the managed properties script first, it wouldn’t find any of the custom crawled properties as there wouldn’t be any extras.
When the managed properties have run correctly, it’ll show as below.
Do a comparison of the managed properties and crawled properties between the old search service application and the new one to confirm it’s the same amount.
Go into SharePoint Central administration to the ‘Manage Service Applications’ page. Click the space next to your new Search service so it’s selected and click permissions in the top ribbon, copy the accounts that are in your old search service to the new one here. Alternatively, you’ll need the account that’s administrating the search service, as well as the account that’s running the User Profile Service for people search, the accounts should have full control.
Now open the new Search Service Application & the old Search Service Application in separate tabs, go to the Crawl rules, copy any of the Crawl rules from the old search service to the new.
Ensure the content sources have also been copied across.
The last step before running a full crawl on your new Search Service is to restart the Search service
For a full crawl, if you have multiple content sources, it’s best to try first on the smallest content source, in most occasions this is the People Search content source, as this is against the number of users in the farm, if people aren’t using their my sites (which is the case normally) this shouldn’t take long at all as there will be less data to crawl.
Once you’ve crawled all the content in your new Search Service, ensure the schedules for the crawls have been setup correctly.
When you are completely happy with the new Search service where you can see there are items it has crawled, it’s time to make this live. Currently your old search service application is still live with all previously crawled content in the database. To change this to the new Search service, navigate to Central Administration –> Manage Web Applications –> highlight the SharePoint Web App and select ‘Service Connections’ in the ribbon. Select the proxy that relates to the newly created Search Service application.
This will swap over your old search service for the new search service.
It is worth noting, doing it this way will place heavy stress on your SQL Server, both CPU & Storage. Therefore ensure your SQL Server can cope this the strain. (as well as the app servers).
Information around SharePoint Search
Search Databases
The Search service application has four databases which each have separate roles in supporting SharePoint. When the search service application is created, the four databases are created which are the search administration, analytics reporting, crawl store & link database.
Search Administration
The Search administration database hosts the Search service application configuration and handles crawl state orchestration, including the content source crawl history.
Analytics Reporting
The Analytics Reporting database stores the results for usage analysis reports and extracts information from the Link database when needed.
Crawl Store
The Crawl Store database stores the state of each crawled item and provides the crawl queue for items currently being crawled.
Link
The Link database stores the information that is extracted by the content processing component and the click through information.
New Search Service Application
For a new Search Service application, ideally a new application pool should be created too. The code below will create a new application pool, search service & search proxy.
As this application pool will be used against Search, a search account is used. When the Search service application has been built, it’s ideal to check the SQL Server to confirm these are installed at the location you require and that they’re all there with the naming convention you require. If the naming convention is wrong, start over again.
OLD/INACTIVE Topologies
Deleting an old or inactive topology can be achieved in PowerShell too.
run:
Get-SPEnterpriseSearchTopology
There should be more than one however, only one should be active, an inactive topology can be removed if required.
Search Permissions check
Permission checks
SharePoint Search Service account:
* Domain user account
* Must not be a member of the Farm Administrators group
* Must not be a member of the Farm Administrators group (to avoid crawling unpublished versions of documents)
* Read access to content sources being crawled
* Web Application(s) (done automatically)
* Member of the farm administrators group
Content Sources
By default when a search service application is created, one content source is also created which is usually called ‘Local SharePoint Sites’ within this, it should contain two urls, the intranet site and the mysites to which it’s set to crawl.
The current setup has the top level Central Admin address which crawls everything in one however, it might be wise to split this into two content sources to separate the crawls and therefore less strain at a certain time should a full crawl be required.
Types of Crawls
Since the release of SharePoint 2013, Microsoft released a new type of crawl that wasn’t available in previous SharePoint versions, which is the continuous crawl. In every SharePoint Online environment, this is set to continuous and cannot be changed as the back end is managed by Microsoft themselves. So in SharePoint 2013 we have three different crawls, the continuous crawl, incremental crawl & full crawl, below is the difference between them all.
Full Crawl
Crawls all content under content source.
When to do a full crawl
* SharePoint Service Packs/Cumulative Updates
* Software Updates
* Crawl rules added, modified or deleted
* Changes to managed metadata
* If there hasn’t been any full crawl of the site
* If a crawl has been stopped, the next crawl will be a full crawl
* ASPX page changes
* Database changes
Incremental Crawl
Crawls content which has been added or modified after the last successful crawl, index only updates when the crawl is completed.
For an incremental crawl, once started you’re not able to launch a second crawl in parallel on the same content source, changes that occur during this crawl will need to wait until the next crawl has run in order to populate the index. The schedule for the incremental crawl will determine how long someone will have to wait for their updates.
Continuous Crawl
Crawls content in 15 minute intervals, if the crawl hasn’t completed in this time then a second will kick off and so on. The index is basically updated continuously and won’t stop unless manually disabled.
For a continuous crawl, this runs at regular intervals. The major difference between the two crawls is a continuous crawl allows further crawls to run in parallel, so you wouldn’t have to wait an hour if you made a modification to a document during a crawl, it would be caught every 15minutes when a crawl is ran. When a continuous crawl is in progress, this cannot be paused or stopped, only disabled, to disable this we’ll need to edit the content source and choose ‘enable incremental crawls’.
Please do get in touch should you require assistance in Search Topologies for SharePoint 2013, 2016 or 2019
I’ve recently had an issue where there are over 2,000 items in a lookup and trying to search for the one you want was a huge pain, the code below can find certain text in the lookup options and exclude these, doing so reduces the amount of values you see and more user friendly for the end users.
From the script below, ‘Electronic Device’ was my column name, which also was a required field. The term I was looking for was “OLD” (as old devices were no longer required and therefore flagged old).
When you have a Lookup column you may find some results you don’t want your end users to select, for instance in my example below, the column name is ‘Team Name’ which is also a required field. This column basically shows every single team.
What the script below does is prevents the user from saving the form if “Human Resources” or “–Select a Team–” have been chosen. It also provides text under the specific column to show an error message “Please select a different Team”. (last section of the code below to see where to place this).
The code below can be amended to be a Choice column rather than a lookup by changing the getTagFromIdentifierAndTitle(“select”,”Lookup”,”Team Name Required Field”); to your column.
<script>
function getTagFromIdentifierAndTitle(tagName, identifier, title) {
var len = identifier.length;
var tags = document.getElementsByTagName(tagName);
for (var i=0; i < tags.length; i++) {
var tempString = tags[i].id;
if (tags[i].title == title && (identifier == “” || tempString.indexOf(identifier) == tempString.length – len)) {
return tags[i];
}
}
return null;
}
function PreSaveAction(){
var oTeamName = getTagFromIdentifierAndTitle(“select”,”Lookup”,”Team Name Required Field”);
var blockName = oTeamName.options[oTeamName.selectedIndex].text;
if(blockName.indexOf(‘–Choose a Team–‘)==0||blockName.indexOf(‘Human Resources’)==0){
alert(“Please select a different Team”);
$(“#tname-error”).text(“Please select a different Team”);
return false;
}
return true;
}
When patching a lot of SharePoint farms, you tend to come across a lot of different issues, I’ve noticed this issue come around more often than most in load balanced farms (which is every farm nearly!).
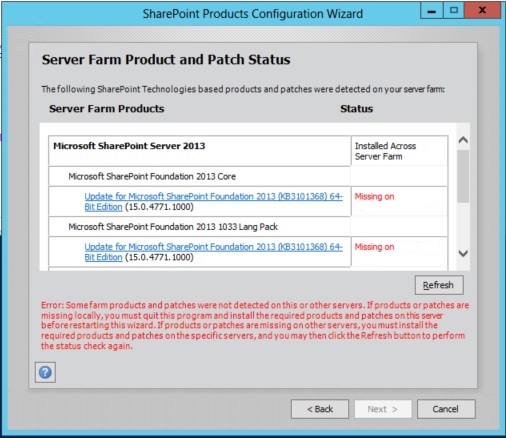
So the scenario I have a lot is patching 3-6 servers, when patches are applied, I run the PSConfig command or PSConfigUI and this is where the issue happens.
From the image above, when I try to run PSConfigUI I get the error, this is after patching all the servers in the farm and waiting to run the config wizard. SharePoint seems to think the rest of the servers in the farm don’t have the patches required however, I’m 100% sure these were installed on each server.
So how would I get SharePoint to understand that every other server in the farm has this patch that’s required? Well after a little digging in PowerShell I’ve found a command that gets the product on a local machine.
If you only run this on one server, you’ll notice the error again. To fully correct this, you’ll need to run this on every server you’ve patched in your farm so the config wizard can recognise the patch level applied.
So I find this issue comes about a lot of the time for female users, reasons being is when they get married, they take the mans surname. So when their name changes in AD, this doesn’t automatically reflect the same in SharePoint.
When Active Directory Syncs with SharePoint User Profile Service, it also does a sync in parallel with the User Information List (UIL). When new users are added or modified, these users will be added to the UIL. Unfortunately, when user names are changed, this doesn’t always update the UIL and therefore creates a second account for the new updated surname account.
To fix this, we have to merge the accounts together and delete the old one. Without carrying this out, you will probably notice that SharePont still uses your old account which you’ll notice in the top right corner of SharePoint.
So firstly you can check the UIL by going to the url below
http://YOURSITEHERE/_catalogs/users/simple.aspx
Following that, you’ll get a list of users that are in SharePoint, you can also find the users by going to Site Settings, People and Groups. Change the URL at the end to look at MembershipGroupId=0, the full URL can be seen below using my own site.
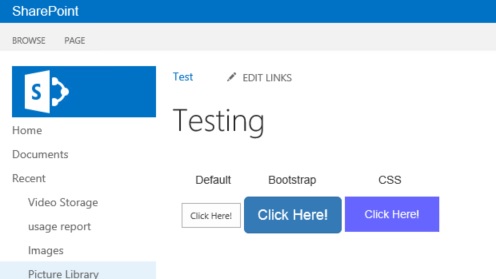
So there are a few ways of creating custom buttons in SharePoint however, I like my buttons to be noticeable so I tend not to use the standard button however, I’ve shown below how to create buttons using basicbutton, Bootstrap & CSS.
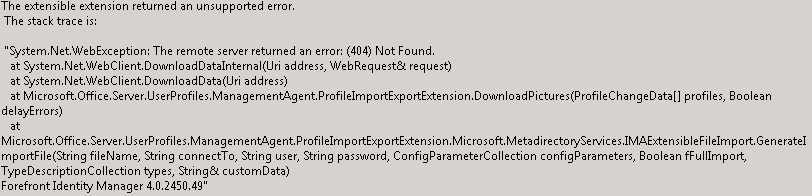
Over the past month I’ve come across an issue where the ForeFront Identity Manager provides an issue which relates to the User Profile Sync Service. So if you’ve been hunting around on Google you’ll probably notice that there are multiple ways of fixing this.
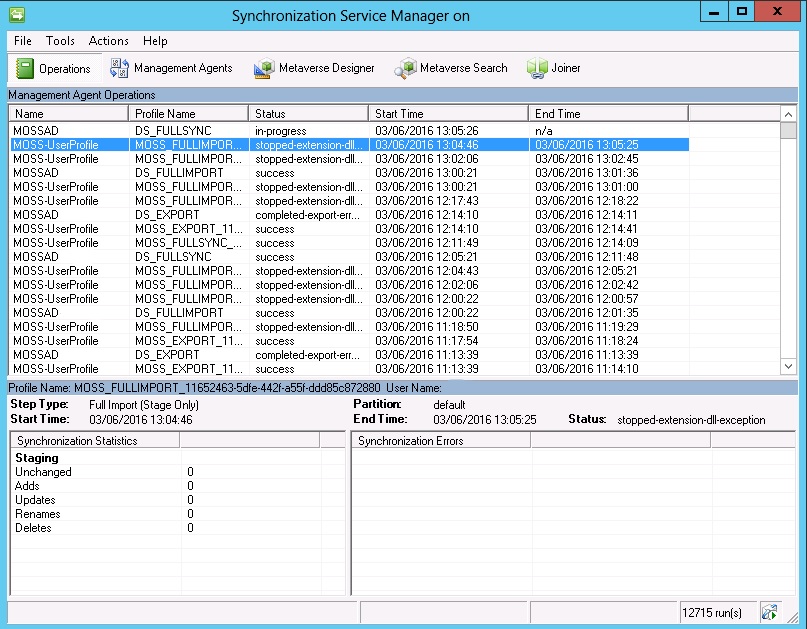
There could be a few issues that this relates to, in my case this was due to peoples profile pictures that have an incorrect URL. Consider the following scenario…If you have a generic picture for all new users until they populate their own picture and this picture gets deleted, the URL for the profile picture that is against each user will be orphaned, so finding out which users have an orphaned picture will require either PowerShell or querying the User Profile Database to find the picture URLs.
I chose to use a SQL query to find this information.
SELECT RecordID, NTName, PictureUrl
FROM UserProfile_Full
Using the query above, this pulled back all users from the user profile with the details in the select query. When you get this information, look into the URLs to find any incorrect. I noticed that some of the URLs were duplicating so it was rather long and obvious. As there were roughly 12 of these we manually changed this however, I’m sure it’s possible to change this through PowerShell if there is a vast amount.
If you open the Synchronisation Service you’ll be able to monitor the issues involved as well as hopefully being successful.
So in my scenario, I ran a script that takes all SharePoint services offline for when I wanted to start patching, little did I realise (or read the script), it also takes IIS offline to disabled mode.
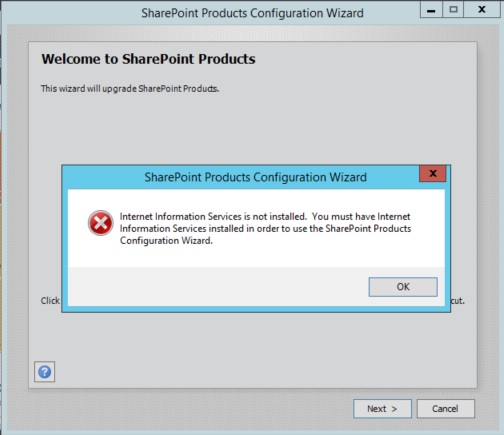
Once I completed the patching, I ran the SharePoint Products Configuration Wizard, as you do. To which I then came across the screenshot below.
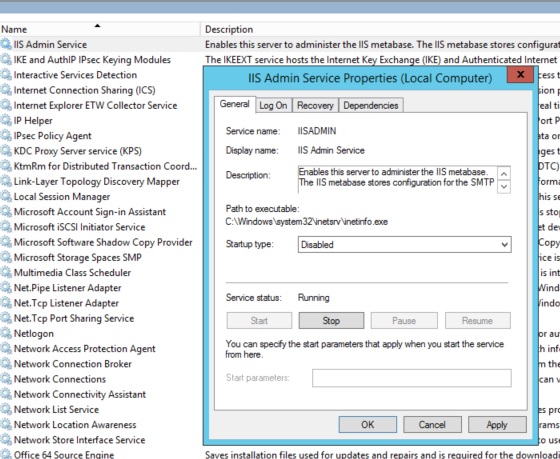
So first off, I know IIS is on the server and SharePoint fully configured so I knew somehow it was disabled. Fortunately I knew where to check this, if you open the start window and type ‘Services’, then look for IIS Admin Service. In my case, this was disabled due to a script I ran, to change this, right click it and go to properties, then set from disabled to Automatic.
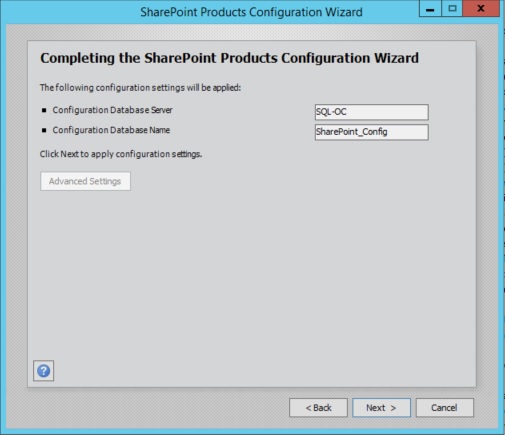
Now try running the SharePoint Products Configuration Wizard and see if you experience the same issue. Hopefully you don’t and you progress to the next screen which will look similar to the below!